The Java 8 Stream API provides comprehensive features for processing file content, listing and traversing directories, and finding files.

1. Outline
The article "Introduction to Stream API through map-reduce" explains how streams provide a way to write SQL-type descriptive queries to process and retrieve data from collections. Like collections contain data in memory, files and directories are containers of data on a disk. Accordingly, the Stream API provides ways to do standard file IO tasks, specifically - consuming files, listing directories, traversing directories, and finding files - through streams.

This article assumes some familiarity with the Stream API. In the next section, we will see some examples of file IO with streams.
2. File IO with Streams
Java 8 added some static methods to Files helper class as part of the Stream API, namely - Files.lines, Files.list, Files.walk, and Files.find. All of these methods do IO operations and can throw IOException, which is a checked exception that the caller must catch or propagate appropriately. Let's explore these methods further with some examples.
For the examples in this section, we have created a directory structure. The root directory of this structure contains some subdirectories and text files. The tree -hC command displays the directory hierarchy along with the file sizes, as shown below:
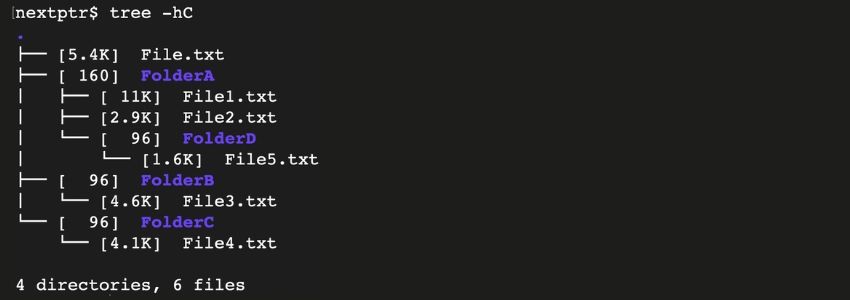
We run all the examples in this root directory.
2.1. Ingesting a file with Files.lines
The Files.lines convenience method returns a stream (Stream<String>) of lines read from a file, which can be lazily processed into useful data. Suppose we want to gather all the unique words from a file; we can do so as follows:
try (Stream<String> lines = Files.lines(Path.of("./File.txt"))) {
Set<String> words = lines
.flatMap((l) -> Stream.of(l.split(" "))) //Split & gather words in a flattened stream
.collect(Collectors.toSet()); //Collect words in a set
//....
} catch (IOException e) {
e.printStackTrace();
//...
}
Note that, the lines from the stream are split into arrays of words which are flattened into one stream (also Stream<String>) by the flatMap operation. Then the tokenized words from the flattened stream are collected into a set. If the words need to be lexically analyzed and filtered before they are collected, we can do so by applying a filter operation before collecting the words in a set.
Also note the use of try-with-resources statement above, which ensures that the stream is closed at the end of the statement. The Stream's base class BaseStream implements the AutoCloseable, so a Stream can be used with the try-with-resources statement as above. The streams returned by the Files.lines, Files.list, Files.walk, and Files.find enclose one or more IO resources that should be closed to avoid the resource leak.
2.2. Listing a directory with Files.list
Listing a directory is like a breeze with streams. The Files.list method returns a stream of paths (Stream<Path>) of all the entries in a directory. For instance, the following code prints all the direct subdirectories under a given directory:
try(Stream<Path> paths = Files.list(Path.of("./"))) {
paths.filter(Files::isDirectory) //Filter subdirectories
.forEach(System.out::println);
/* Prints (order could be different):
./FolderA
./FolderB
./FolderC
*/
} catch (IOException e) {
e.printStackTrace();
//...
}
2.3. Traversing a directory with Files.walk🚶♂️
The Files.list is quite a helpful method. However, if we want to collect some information from nested files and folders under a directory, we need a more powerful utility. The Files.walk method can traverse down a given folder for a specified depth and return a stream of paths, which can be lazily processed to retrieve sought data.
In the following code, we use Files.walk to calculate the sum of sizes of all the regular files under a folder:
try(Stream<Path> paths = Files.walk(Path.of("./"), 3)) { //Traverse for depth 3
long sum = paths.filter(Files::isRegularFile) //Filter regular files
.mapToLong((p) -> p.toFile().length()) //Map to file size (long)
.sum(); //Calculate sum of file sizes
//...
/* 'sum' is sum of sizes of these files:
./File.txt
./FolderA/File1.txt
./FolderA/File2.txt
./FolderA/FolderD/File5.txt
./FolderB/File3.txt
./FolderC/File4.txt
*/
} catch (IOException e) {
e.printStackTrace();
//...
}
2.4. Finding files with Files.find
A keen reader might have noticed that we can use the Files.walk method to search files under a directory. However, finding files is such a standard operation that it deserves a distinct method for it. The Files.find, as its names suggest, returns a stream of paths that satisfy a given predicate. In the code below, we discover all the regular files that have at least 10KB size:
try(Stream<Path> paths = Files.find(Path.of("./"), 3, (p, a) -> { //Predicate
return a.isRegularFile() &&
a.size() > 10240; //Regular file with size > 10KB
})) {
paths.forEach((p) -> System.out.println(p));
/* Prints:
./FolderA/File1.txt
*/
} catch (IOException e) {
e.printStackTrace();
//...
}
In another example below, we search all the files with extension ".txt":
try(Stream<Path> paths = Files.find(Path.of("./"), 3, (p, a) -> { //Predicate
return p.toString().endsWith(".txt"); //Extension ".txt"
})) {
paths.forEach(System.out::println);
/* Prints (order could be different):
./File.txt
./FolderB/File3.txt
./FolderC/File4.txt
./FolderA/File2.txt
./FolderA/File1.txt
./FolderA/FolderD/File5.txt
*/
} catch (IOException e) {
e.printStackTrace();
//...
}
3. Closing Words
Stream API provides excellent support for the standard file IO operations in the form of convenient static methods of the Files class. These methods can be used instead of the tedious boilerplate loops to process data on a filesystem.